Stock XPert - Hackathon
Table of Contents
Stock XPert for the “Cohere - Cracking the AI Code: Enterprise AI” Hackathon
In Feb. of 2024, some of us at DXC / Luxoft took part in the Cohere AI Hackathon. The hackathon was a week long remote hackathon focused on building an application with Cohere’s AI tools. This was prior to Command-R being released, and as such was a difficult task due to the Cohere model at the time not being on par with frontier models such as GPT-4. However, I really liked Cohere’s set of tools, such as the Classifier & Summarizer endpoints.
Since the hackathon was in collaboration with the NYSE, we decided to build an MVP for a automated stock analysis assistant. At it’s core, this is a natural language wrapper around a finance API, utilising certain prompting techniques such as ReAct to do so. Since we were on a time limit, we built the front-end with streamlit.
Backend - to framework or not to framework
This project used an AI framework to orchestrate the calls to Cohere. Initially I did not want to go down this route, since all we wanted to do was apply a natural language interface to API commands and then process the result. It seemed that there wasn’t any need to add complexity by using a framework.
The issue with frameworks is twofold:
- (1) Frameworks will wrap any API calls to a model within (multiple) class(es). Not only does this make it harder to give instruction to the model, but debugging issues with latency & weird responses becomes an ordeal of digging through the library code.
- (2) Rather than working with the AI directly, and adjusting the prompts yourself, you are guided towards using other peoples prompts, which may not have been optimized for the Cohere model. The frameworks become opionated and not neccessarily optimal.
However, the benefit of frameworks is that it allows developers with less experience in AI to quickly spin up an MVP. Due to our time constraints we decided to go with a framework called CrewAI, and vowed to refactor the code to not use a framework if / when we decide to productionize the project.
CrewAI at the time was a new-ish framework for orchestrating AI agents. I was quite impressed with it, but it did still suffer from the two issues I described above. Using CrewAI, we produced 3 ‘agents’ which could perform different financial tasks, as well as a ‘Master’ agent, which could invoke the other 3 agents, and produce a report from their results.
The 4th agent (RAG over ESG documents) did not use a framework. I had done enough RAG applications by this time to quickly spin up a working prototype, which allowed the users to ask questions like “What goals did Microsoft acheive in the 2022 ESG report?”
The Agents
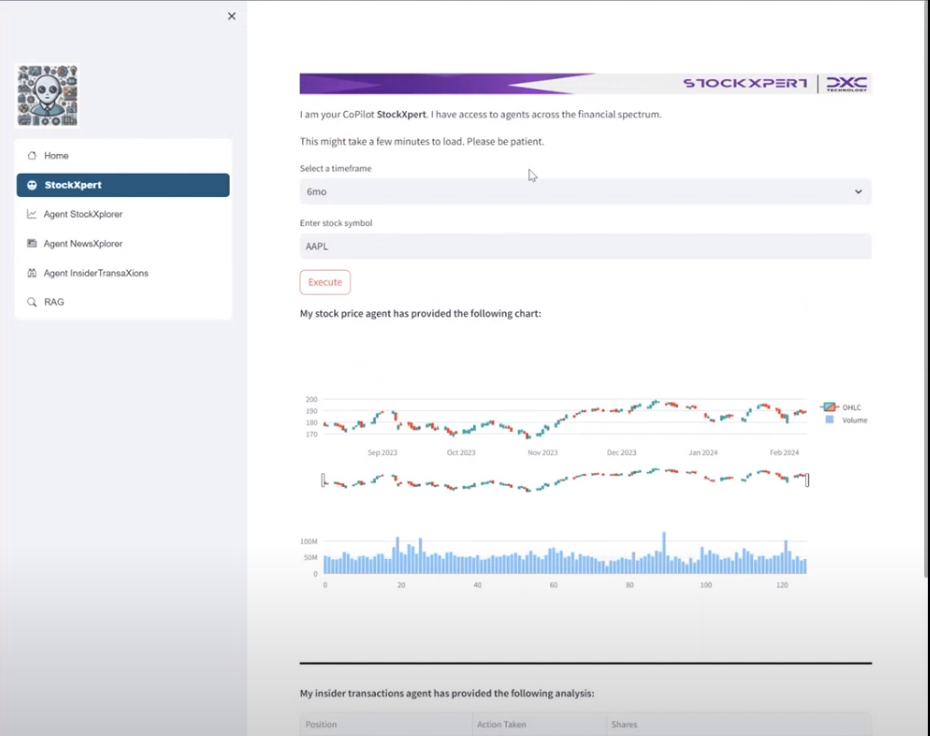
(Agent 1) Individual Stock Analysis
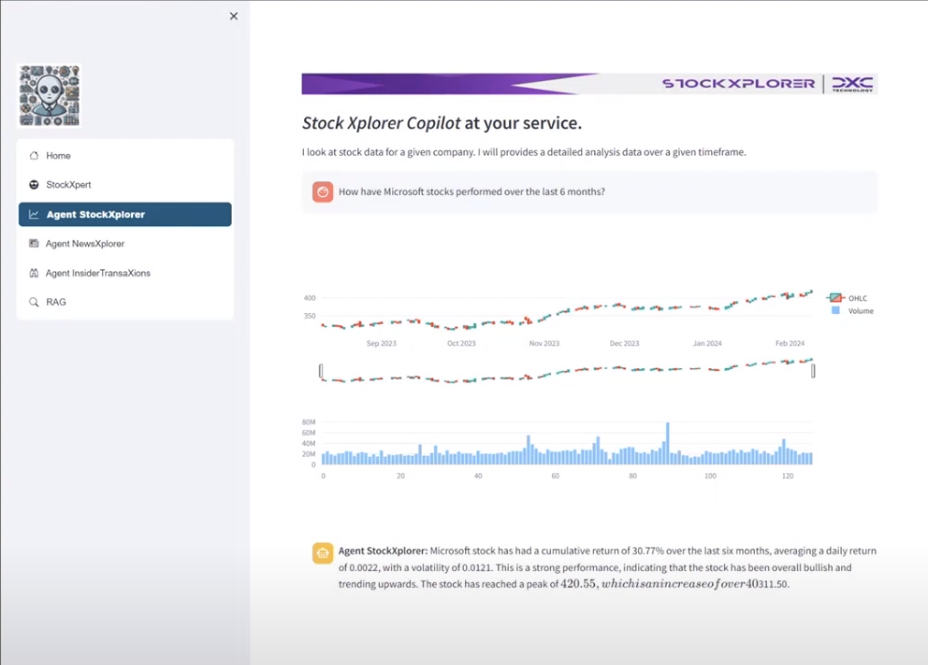
This agent queried the yfinance API for stock data about a company over a specified range. For example, you could ask “How have Apple performed over the last 6 months”, and the agent would figure out the query by solving a set of tasks. In this case:
- (1) Determine the ticker required.
- “How have Apple performed over the last 6months”? -> “AAPL”
- (2) Determine the timeframe required.
- “How have Apple performed over the last 6months”? -> “6mo”
- (3) Combine the results into required format for API.
- “AAPL#6mo”
- (4) Given data collected from API provide a natural language description.
- “Apple have performed well over the last 6 months. We can see that … "
The reason we split the task down into essentially its atomic components here is mainly due to the limited capabilities of the Cohere model, and we found that allowing the model to break down the tasks and feeding the results of each step back into model to produce better results. A frontier model could combine steps 1-3 into one step.
See an example output of this agent below.
(Agent 2) News Sentiment Analysis
This agent had two main tasks.
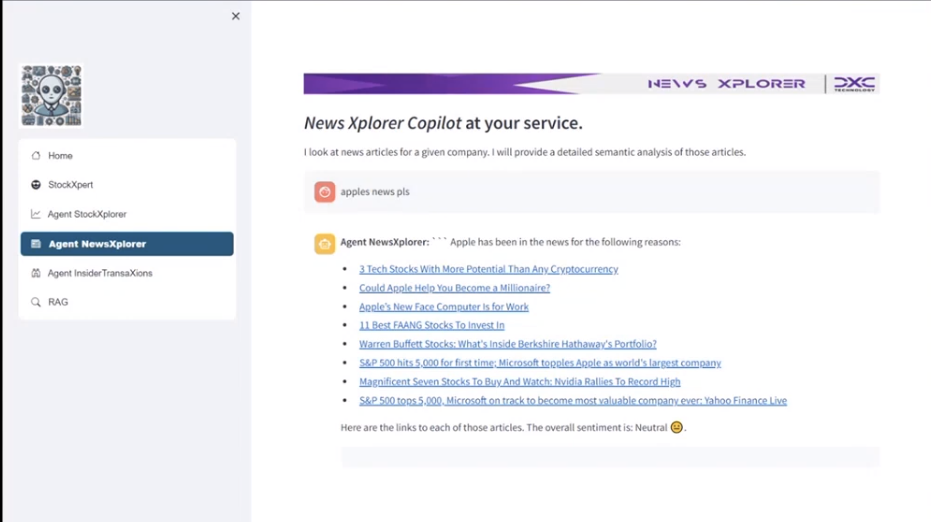
- Get the news articles for a specific company following similar steps to Agent 1.
- Provide a sentiment analysis of the news article.
In order to provide this sentiment anaylsis, we fine-tuned a Cohere classifier model. Once the headlines of each article were retrieved we piped these into our classifier model, and then piped the output of that into a LLM to produce the final result displayed to the user. See an example below
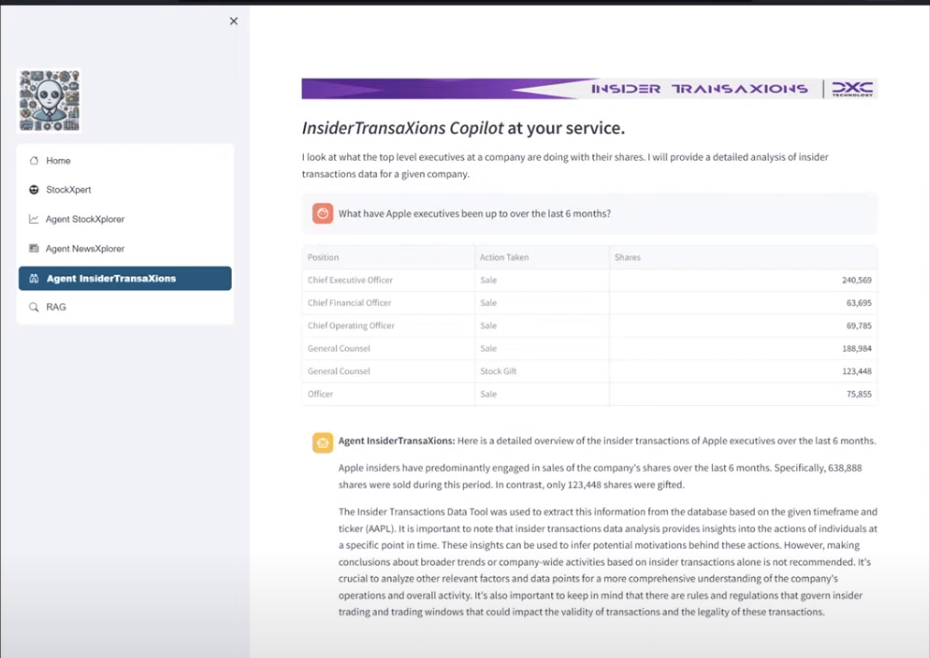
(Agent 3) Insider Transactions
This agent acts very similar to the Stock Analysis agent in terms of the steps required, but the output of the first 3 steps is piped into a different API.
(Agent 4) ESG RAG
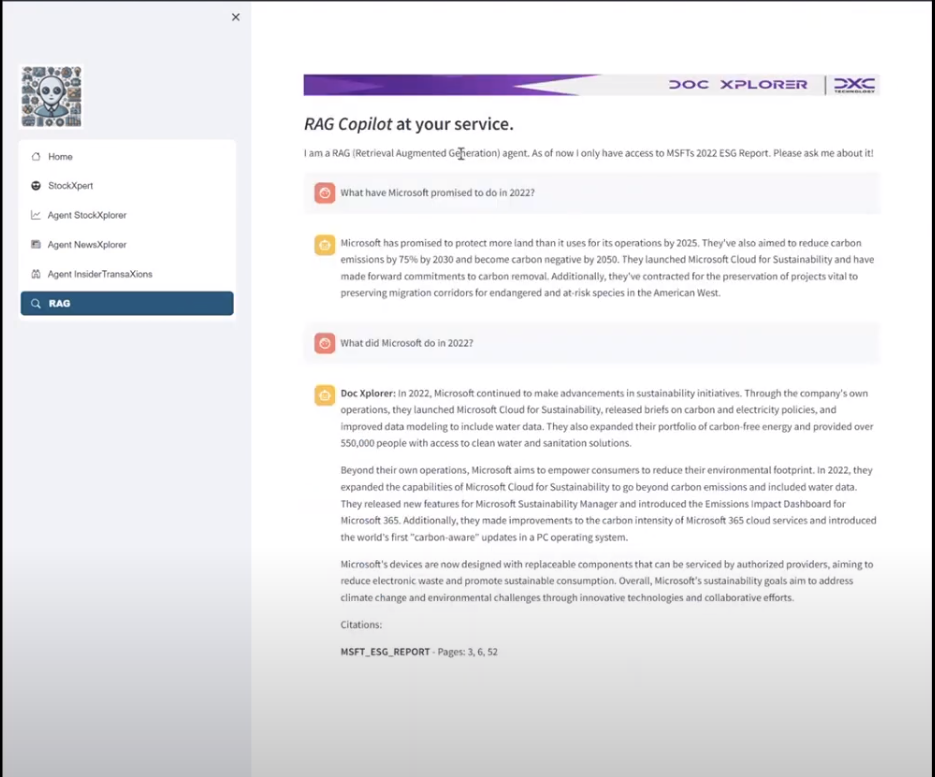
In order to use the ESG reports effectively, we had to perform some data prep. We split up the ESG document by page, and used the Cohere summarizer API to summarize each page, ensuring that key words and concepts were kept within the summary.
These pages were then embedded & vectorize in order to be stored in a Weaviate vector database. This is then queried over using the similarity between the question and each page to return the relevant sections of the ESG document.
Master Agent
As mentioned, the master agent can invoke agents (1), (2) & (3) and then uses their outputs to build an overall report.
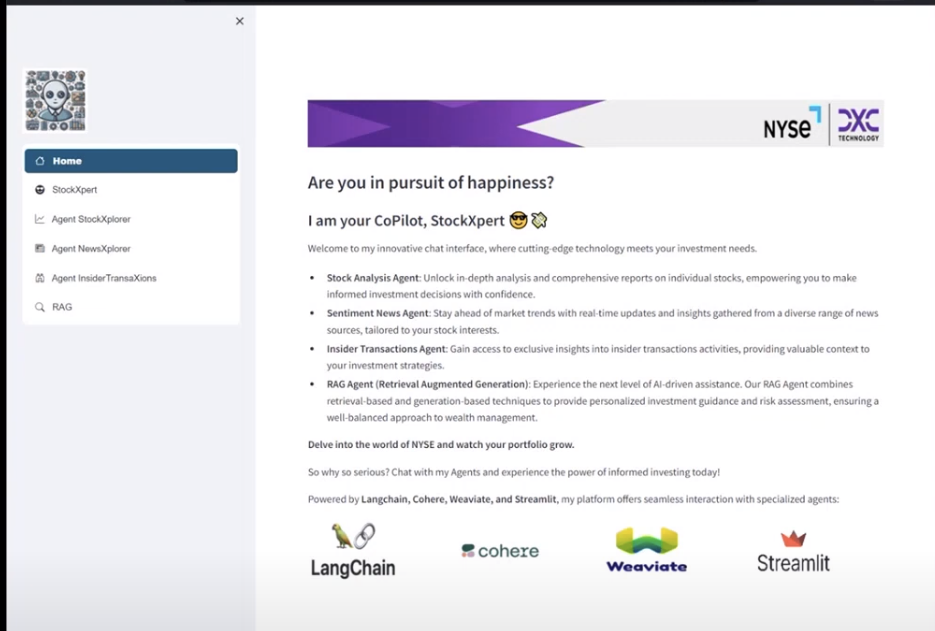
Frontend
The frontend we decided to use was Streamlit. This was my first time using Streamlit and I was very much impressed. Two of us were able to spin up a well oiled, good looking frontend in a single (late) night. See the homepage below.
Outcome
The hackathon went well, and the Cohere/NYSE team were impressed with our application - giving us the 3rd place prize in response to our efforts - Cohere’s Twitter Post on the Hackathon Results. This netted us $200 dollars each in cash which was pretty cool - my first ever winnings from a hackathon!
I think the project was fun & interesting. However, I don’t actively need real time stock analysis tool, so I’ll likely take the backbone of the project and experiences learned from using agents, and incoporate those skills into gptcotts.
For questions / comments, please reach out to me on the everything app.